文泉学堂正版免费电子书资源爬取
这件事还得从一只蝙蝠说起……
寒假回家正好赶上了2019-nCoV的爆发,在昨天得知清华大学出版社出品的在线学习平台文泉学堂免费开放所有电子书的在线阅读,于是想着能不能把上面的正版电子书给下载下来。
上去打开发现用的是文泉学堂自己的在线电子书阅读器,然后抓包查看发现是一张一张的图片。给一个图片url的参考(此url现在已经不能用了,原因下面有):
分析一下这个url:
从域名到img/应该是固定格式,2175744经过对整个网页加载过程的抓包

可以看到应该是bid,推测是book id,看一下这本书的其他页面图片都是2175744,看一下别的书的bid与之不同,再根据书籍介绍页的url(https://lib-nuanxin.wqxuetang.com/#/Book/2175744)可以确定这应该就是book id。
然后分析不同页面的不同url,可以推断k参数前的1是页面(昨天测试的时候这个数字无论怎么改只要参数k不变所得到的页面就不变,k中也有关于页面的信息,在昨天的测试中k起到决定性作用,但今天测试仿佛不行了,必须url中的当前页数和k中的当前页数吻合才可以下载)
然后来聊聊这个k,这个k才是下载的关键。首先由两个点号分成三段然后前两段是base64编码的,基本可以肯定是jwt(JSON Web Tokens)认证。我们用jwt.io对其解码
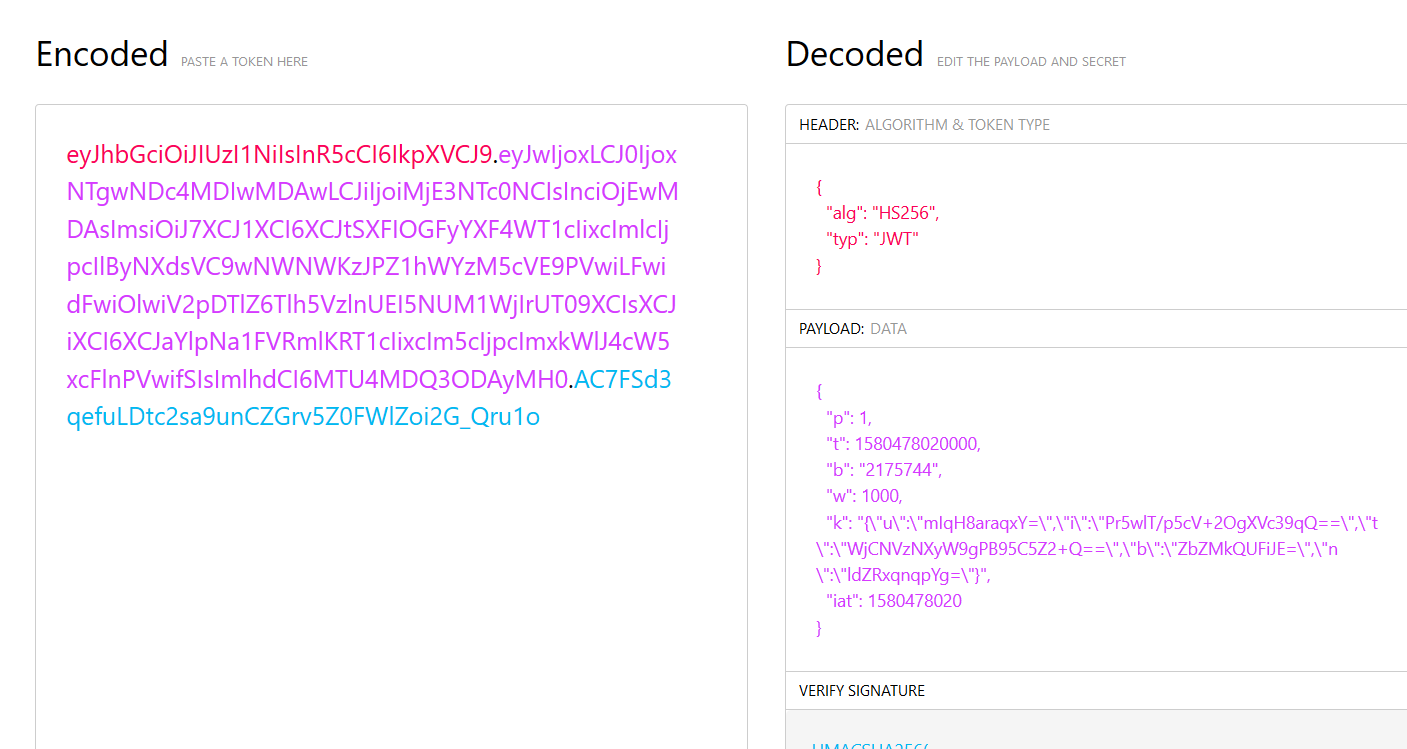
根据jwt的定义,第一部分(HEADER)就是写了jwt和其签名方式(HS256),第二部分是要传输的信息内容,第三部分是用密钥签名认证,只有签名正确才是认证成功,通常来讲密钥存储和签名都是放在服务端以防止签名泄露的。
先看第三部分的签名密钥,抓包(也可以通过分析阅读页面的源代码)可以看到请求了一个js文件(https://lib-nuanxin.wqxuetang.com/static/read/js/read.v5.3.1.722eb.js)
代码一片混乱可以猜测是整合或者压缩过的,可以使用Firefox的F12里面的调试器来整理代码(也可以使用PhpStorm来reformat,不过格式好像是PHP的格式)。
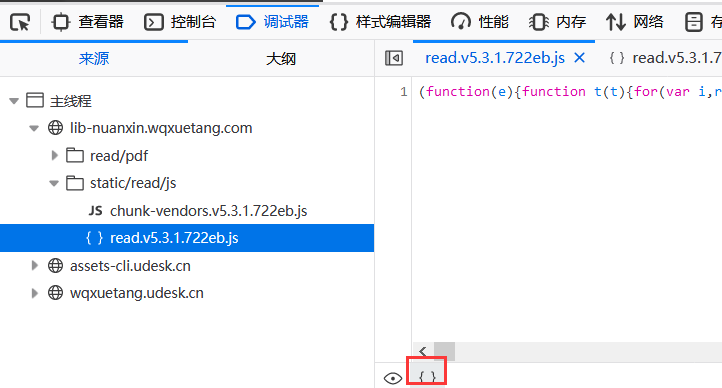
美化完成后复制进PhpStorm,一番寻找找到了getJwt函数:
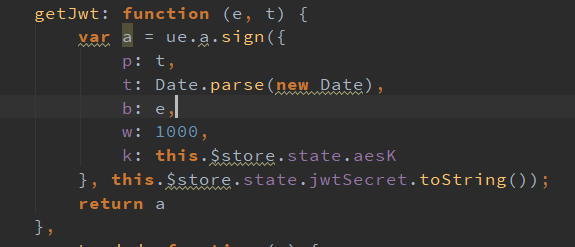
其中的jwtSecret应该就是签名的密钥,本以为这个是存储在浏览器本地存储区的,结果在PhpStorm中直接按住Ctrl点击直接定位到了变量设置的代码

得到jwtSecret,放入jwt.io校验通过。
然后分析第二段(即PAYLOAD数据段)

比对多个页码的图片url,可以发现p是页码,t很明显是时间戳(也可从上面的代码中看出),b是bid(book id),w不知道是什么,但固定都是1000(在JS脚本中写入),而这个k又是重点,多次比对,其中的t是时间戳的加密,整个t是一个json表,每一项的数据都是加密过的,看代码调用了很多函数。
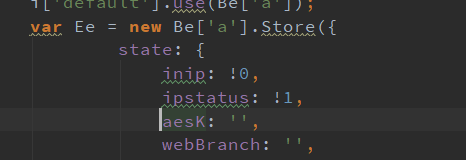
首先初值是空串
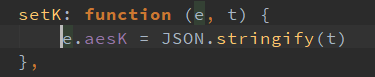

然后做了各种处理得到的(并没有搞懂QwQ)。
但是最后发现好像是经过了一次网络请求。然后重新看看抓包,发现在https://lib-nuanxin.wqxuetang.com/v1/read/k?bid=2175744的请求中会返回k的内容。根据JS代码每五分钟请求一次但实际每一分钟请求返回的k就会变化推测每一分钟更新一次(对t进行加密,t是精确到秒的时间戳),五分钟失效(这也是为什么上面给的页面url现在已经无法使用了的原因)。也就是说我们不需要管这个k是怎么生成的,加密可能也是在服务端实现,我们仍需要请求这个。

浏览器直接请求,发现也是一个json,其中的data项就是我们想要的k,根据请求url可以猜测每本书的k应该是不一样的。然后对每一个引号比对jwt中的内容做转义处理,修改p,然后用密钥签名重新打包成一个jwt去请求,会发现下载来只有5字节,是一个损坏的图像,此时在Header中加入原来抓包抓到的书页图像Header中的refer就能正常显示了(最终发现第二段中的未加密的t和iat好像没啥影响,k中加密的t才是决定性因素)
最后结合抓包的内容分析可以看出,https://lib-nuanxin.wqxuetang.com/v1/book/catatree?bid=2175744是这本书对应的目录json,https://lib-nuanxin.wqxuetang.com/v1/read/initread?bid=2175744中可以获取全书的总页数,对应起来就能写一个完整的脚本用于批量下载、生成pdf文件,可以通过https://lib-nuanxin.wqxuetang.com/v1/search/inithomedata?type=&size=10&pn=1来获取每个图书的bid(其中size=10是每页展示的图书数,可以根据图书数量一次性获取所有图书的bid,比如可以看到一共427页,每页10本共4270本,实际4263本,size改成4263请求下来直接查找numid就是每本书的bid了)
附:代码实现 by MaPl & Hanabi 由于某些原因暂不公开代码,自己试试吧,并不复杂